前回のおさらい。今回したいこと。
前回はseleniumを使ってカブドットコム証券にログインする方法を書きました。seleniumを使えば簡単にログイン処理をすることができます。
今回は、ログイン後に実際にスクレイピングによって、必要なデータをpythonまで持ってくる方法を考えます。
kabuナビでスクリーニングする
|
1 |
driver.find_element_by_link_text('kabuナビ').click() |
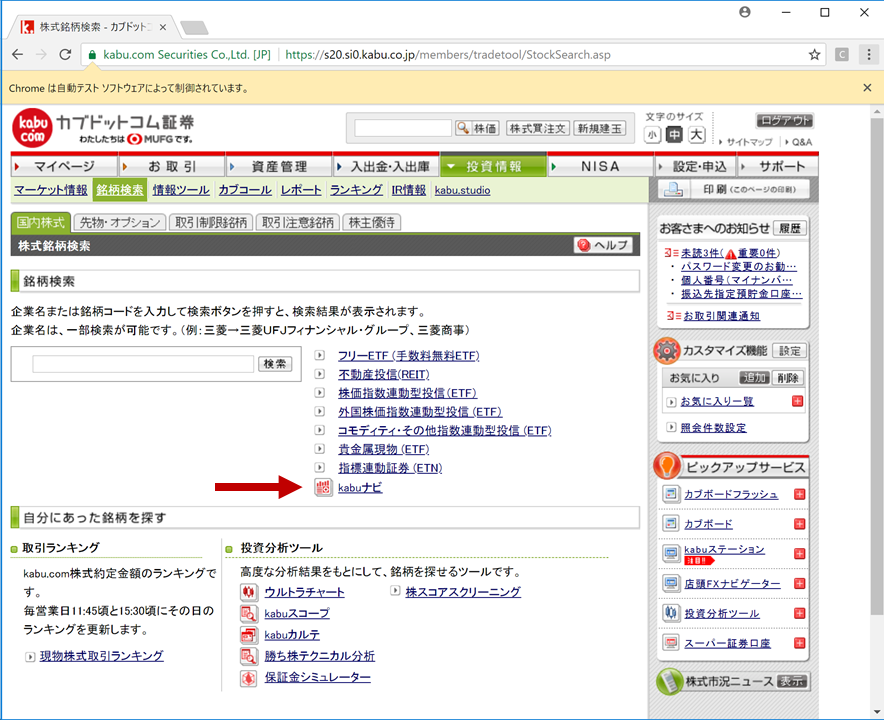
カブドットコム証券にログインすると以下のようなページがでてくると思います。
スクリーニングには赤い矢印の部分にある、kabuナビを用いるので、kabuナビのエレメントをクリックします。
|
1 2 |
driver.switch_to.window(driver.window_handles[1]) driver.switch_to.frame(driver.find_element_by_tag_name('iframe')) |
kabuナビをクリックすると新しいウインドウが表示されるので、操作するウインドウを切り替えます。その後詳細設定をクリックするのですが、ウインドウ変更後に要素を探しても、見つからない旨のエラーが返ってきます。私はここでつまずきました。HTMLにはインラインフレーム要素というものがあり、要素を入れ子状に埋め込むことができます。このインラインフレーム要素にフレームを切り替えないとインラインフレーム要素を探してクリックすることはできません。
|
1 2 |
sleep(20) driver.find_element_by_css_selector("body > div.kabu_top > div.top_menu > div:nth-child(2)").click() |
また、新しいウインドウを開いた際に表示される前に操作を行ってしまうと要素が見つからずエラーが返ってきてしまいます。そのため、読み込みのために操作を一時停止するsleepをいれ、その後、スクリーニングのための詳細検索のページに移動します。
|
1 2 3 4 5 6 7 8 9 10 11 |
driver.find_element_by_css_selector("#favorite_button").click() button = driver.find_element_by_class_name("ui-menu-item") hover = ActionChains(driver).move_to_element(button) hover.perform() sleep(5) button2 = driver.find_element_by_css_selector("#ui-id-6 > div") hover = ActionChains(driver).move_to_element(button2) hover.perform() driver.find_element_by_css_selector("#ui-id-6").click() |
次にお気に入りから自分の設定したフィルタを適用します。このお気に入りの設定は事前に自分でしておく必要があります。PERやPBRなどの基本的な指標から、有利子負債比率や売上高変化率など細かな設定を行っておくことが出来ます。この細かい設定が可能なところが証券会社のスクリーニング機能を使うメリットです。
マウスオーバーによってひらくメニューは、通常状態でエレメントとして探すことが出来ないため、seleniumで擬似的にマウスオーバーする必要があります。その時に使えるのがActionChainsです。
|
1 2 3 |
sleep(5) driver.switch_to.frame(driver.find_element_by_id("detailFrame1")) driver.find_element_by_id("topSearchBtn").click() |
最後に検索ボタンを押すことで、スクリーニング条件に合致する株式の一覧が表示されます。
|
1 2 3 |
sleep(5) data = driver.page_source raw_data = pd.read_html(data, flavor='bs4') |
表示された株式の一覧は以前に株価データサイトから取得する記事に書いた株価のスクレイピングと同様の方法でpandasを使ってテーブル形式でそのままスクレイピングを行ないます。
最近のコメント