
初心者がFXで機械学習をする
私は株価のスクレイピングの記事でも書いたように、まったくプログラミングの経験がありません。しかしながら、機械学習に対する漠然と憧れていました。そこで今回はFXで機械学習を行って、上がるか下がるかを予測できるようにしたいと思います。値動きやテクニカル指標を見て取引し、勝っている人がいるということはそのデータをいれてやれば私のような凡人でも聖杯を見つけることができるのではと考えました。初めての機械学習なので、比較的理解しやすいランダムフォレスト法を用いています。
プログラミング前の下準備
今回はGoogleのColaboratryを用いて行いました。Colaboratryは無料で12GBのメモリが使用できます。これは私が使用しいるPCのスペックより高いので、嬉しいのか悲しいのか複雑な気持ちですが、ありがたく使わせていただきます。Colaboratry用のデータの読み込みコード等も省かずにのせていきたいと思います。
まずはFXのデータをダウンロード
FXのデータはHistData.comよりGeneric ASCII形式でダウンロードすることができます。2016年のEURUSD1分足をダウンロードしました。
実際に機械学習
|
1 2 3 4 5 |
%matplotlib inline import numpy as np import pandas as pd import matplotlib.pyplot as plt |
まずは必要なライブラリを読み込みます。
|
1 2 |
from google.colab import files f=files.upload() |
次に先程ダウンロードしたファイルをアップロードします。
ここで、参照をクリックして、ダウンロードした場所をひらいてファイルを選択します。
|
1 |
df= pd.read_csv('EURUSDm1.csv', sep=';', names=('Time','Open','High','Low','Close', ''), index_col='Time', parse_dates=True) |
データフレームとして読み込みます。
|
1 |
df.plot(y='Close') |
特に意味はないのですが、プロットして確認したりするのも楽しいです!
|
1 2 3 4 5 |
df2=df.dropna() diff1=df2.loc[:,['Close']].diff(1) diff5=df2.loc[:,['Close']].diff(5) diff10=df2.loc[:,['Close']].diff(10) df3 = pd.concat([df2, diff1, diff5, diff10], axis=1) |
次に終値の差分を取っていきます。diff1は一日前からどれだけ値段が変わったか。diff5とdiff10はそれぞれ5日前、10日前から終値がどれだけ変化したかです。ランダムフォレストは一行のデータだけでモデルを調整するので、始値や終値よりも差分の方が大事なデータになると考えています。
|
1 2 3 4 5 6 |
df3.columns = ['Open','High','Low','Close','Volume','Diff1','Diff5','Diff10'] df4 = df3.dropna() answer = df4.loc[:,'Diff5'].shift(-5) df5 = pd.concat([df4,answer], axis=1) df5.columns = ['Open','High','Low','Close','Volume','Diff1','Diff5','Diff10','Answer'] df5.dropna() |
次に列の名前をそれぞれ整え、空の行を削除します。
今回は5分先の終値がどうなっているかを予測したいので、diff5を前方に5つ分ずらすことで、正解のデータを作成します。
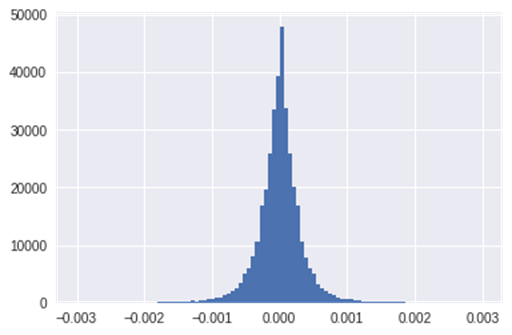
|
1 |
plt.hist(answer, range=(-0.003, 0.003), bins=100) |
ここで、そもそも5分でどれくらい価格が動くのか確認します。ヒストグラムを作成することで5分後の価格の動きの分布をみることができます。
本当はここで、統計的に目標を定めるべきなのでしょうが、なんとなく0.0005動くかどうかを予想したいと思います。ちなみにこれはFXでいう5pipsに相当するので、予想できれば十分に利益が出ると考えられます。
|
1 2 3 4 5 |
df5.loc[df5['Answer'] >=0.0005, 'Answer'] = 2 df5.loc[(0<df5['Answer']) & (df5['Answer'] <0.0005), 'Answer'] = 1 df5.loc[df5['Answer'] <= -0.0005, 'Answer'] = -2 df5.loc[(0>=df5['Answer']) & (df5['Answer']>-0.0005), 'Answer'] = -1 df5=df5.dropna() |
そこで、+5pips以上なら2、0~5pipsなら1、0~-5pipsなら-1、-5pips以下なら-2のラベルを振ります。
|
1 2 |
from sklearn.model_selection import train_test_split trainx, testx, trainy, testy = train_test_split(df5.iloc[:, 0:8], df5.iloc[:,[8]], train_size=0.8, random_state=1) |
いよいよ実際に機械学習していきます。まずは、データをトレーニング用とテスト用にわけます。トレーニング用にはデータの80%を使い、そこで学習した内容を残りの20%のテストデータで検証します。
|
1 2 3 |
from sklearn.ensemble import RandomForestClassifier clf = RandomForestClassifier(random_state=0) clf = clf.fit(trainx, trainy) |
まずは、トレーニングデータで分類器を作成します。
|
1 2 |
print('Train score: {}'.format(clf.score(trainx, trainy))) print('Test score: {}'.format(clf.score(testx, testy))) |
実際にトレーニングデータとテストデータがどれくらいの正解率か確認すると、トレーニングデータでは当然ながハイスコアですが、テストデータでは正解率が50%をきっています。しかし、ここで考えなくてはいけないのは4種類に分類する問題なので、それぞれの正解率が大事てあること、また、5pips動かないと予想して動いた分には単なる機会損失なので実際にお金はなくなりませんが、5pips動くと思ってトレードして逆に行ってしまうと損が出てしまいます。つまり、適合率の高さが重要になってきます。
|
1 2 3 |
y_pred = clf.predict(testx) from sklearn.metrics import confusion_matrix confusion_matrix(testy, y_pred) |
|
1 2 3 4 |
array([[ 375, 2010, 1478, 133], [ 661, 20306, 12883, 297], [ 551, 17643, 13880, 305], [ 255, 1974, 1570, 212]]) |
そこで混合行列を確認します。
5pips以上または-5pips以下だと予想して反対に大きく動かず正解する確率は60%であり、動かないとしても若干予想方向に動くことが多いことが分かります。また取引数もあるので、優位性のあるトレードが行えると考えられます。
こんなに簡単なデータセットで勝てそうな予想ができるなんて!!!!!!と、興奮しましたが、現実はそんなに甘くありませんでした。
幻に消えた聖杯
このシステムを実装しようと考えたとき、ふとトレーニングデータとテストデータの分割の仕方がよくないことに気づきました。予測ためには過去のトレーニングデータによって未来の予想をしなくてはいけません。しかし、私の分割方法ではランダムに抽出しているため、未来のデータから過去のデータを予想してしまうことになります。
|
1 2 |
from sklearn.model_selection import train_test_split trainx, testx, trainy, testy = train_test_split(df5.iloc[:, 0:8], df5.iloc[:,[8]], train_size=0.8, shuffle=False) |
そこで、shuffle=Falseを追加することでランダムに抽出するのではなく、データを前後で分割します。
|
1 |
confusion_matrix(testy, y_pred) |
|
1 2 3 4 |
array([[ 227, 1474, 2532, 376], [ 457, 10656, 21125, 957], [ 390, 10549, 20530, 845], [ 214, 1405, 2416, 380]]) |
そして、混合行列を表示すると、完全に優位性を失っていることが分かりました。適合率もほぼ50%であり、これではまず勝てないでしょう。
やはり、テクニカル要素の追加や、パラメータの最適化を行わないとだめなようです。